This is an old revision of the document!
Introduction to TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning
Week 1:
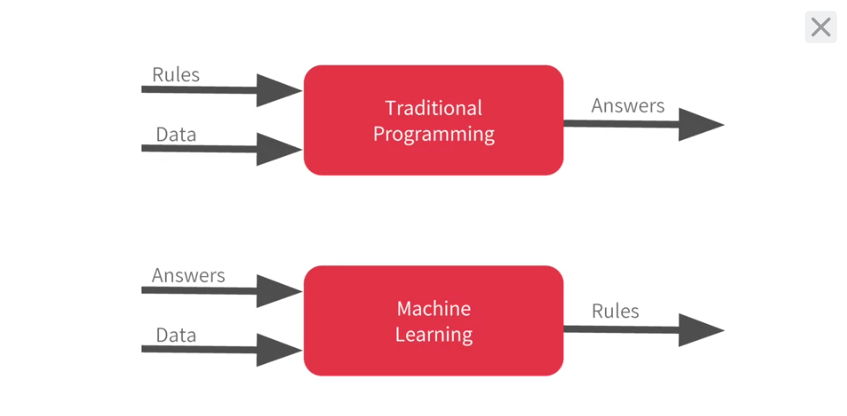
Traditional Programming vs Machine Learning
Hello World of Neural Networks

# One Neuron Neural Network # Dense = Define a Layer of connected Neurons # Only 1 Layer, Only 1 Unit, so a Single (1) Neuron model = keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])]) model.compile(optimizer='sgd', loss='mean_squared_error')
You've probably seen that for machine learning, you need to know and use a lot of math, calculus probability and the like.
It's really good to understand that as you want to optimize your models but the nice thing for now about TensorFlow and keras is that a lot of that math is implemented for you in functions.
There are two function roles that you should be aware of though and these are loss functions and optimizers.
This code defines them. I like to think about it this way.
The neural network has no idea of the relationship between X and Y, so it makes a guess.
Say it guesses Y equals 10X minus 10. It will then use the data that it knows about, that's the set of Xs and Ys that we've already seen to measure how good or how bad its guess was.
The loss function measures this and then gives the data to the optimizer which figures out the next guess. So the optimizer thinks about how good or how badly the guess was done using the data from the loss function.
Then the logic is that each guess should be better than the one before. As the guesses get better and better, an accuracy approaches 100 percent, the term convergence is used.
In this case, the loss is mean squared error and the optimizer is SGD which stands for stochastic gradient descent.